The CCI
The CCI
 Bertinetto & Bertini (2008 and following) proposed a new rhythm metric that heavily differs from the others. Firstly, it has been inspired by previous studies on compensation, in particular by Fowler et alii, of the '80s. Secondly, it is a phonologically driven approach, as it is defined by the two authors. It consists of a modification of the formula of the rPVI, with the duration of each vocalic or consonantal interval being divided by the number of phonological segments that compose it (this implies that geminate consonants and phonologically long vowels count for 2 segments - the authors also provide suggestions on how to treat diaeresis, hyatus, etc.):
Bertinetto & Bertini (2008 and following) proposed a new rhythm metric that heavily differs from the others. Firstly, it has been inspired by previous studies on compensation, in particular by Fowler et alii, of the '80s. Secondly, it is a phonologically driven approach, as it is defined by the two authors. It consists of a modification of the formula of the rPVI, with the duration of each vocalic or consonantal interval being divided by the number of phonological segments that compose it (this implies that geminate consonants and phonologically long vowels count for 2 segments - the authors also provide suggestions on how to treat diaeresis, hyatus, etc.):
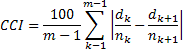
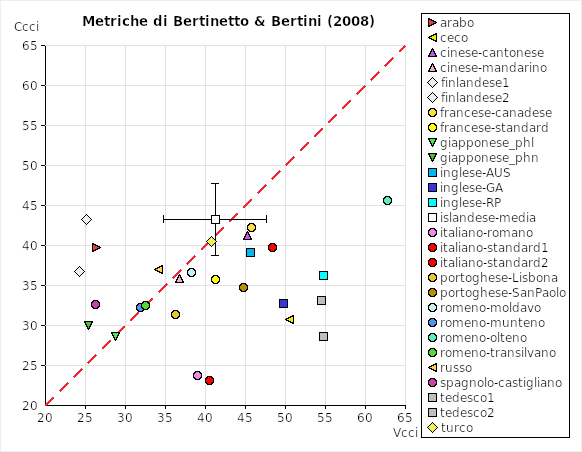
The CCI (Control and Compensation Index) measures the level of compression allowed for in a language, that is to say how much the segments can be lengthened or shortened according to the context: the two authors predict that controlling languages (allowing for a low level of compression, corresponding to the traditional category of syllable-timed languages) should scatter along the bisector, whereas compensating languages (allowing for a high level of compression, corresponding to the traditional category of stress-timed languages) should cluster in the lower right corner of the chart, below the bisector.
Members of the staff of the Laboratory of Experimental Phonetics of Turin have been the first to apply the CCI to languages other than Italian; the results are shown in the charts. The data consist of the narrative The North Wind and the Sun translated into various languages and read by professional or standard speakers (we have used some of the illustrations of the Handbook of the IPA and of the Journal of the IPA, but many samples have been recorded in our laboratory). The recordings have been accurately segmented and annotated independently by Antonio Romano and Paolo Mairano and the final results consist of the average of the values obtained by the two authors. Every dot in the chart corresponds to one speaker (except for Icelandic, for which we have 1 dot for 10 speakers to avoid confusion - the error bar indicates the standard deviation between the results obtained for each of the 10 speakers). The values of the correlates have been computed with the help of Correlatore, with which we have also built the charts.
A detailed discussion of the results can be found in our publications (see the bibliography below). However, it should be noticed that controlling languages (Italian, French, Spanish, ...) are roughly scattered along the bisector, whereas compensating languages (English, German, ...) are roughly distributed in the lower right corner of the chart.
Essential bibliography
- Bertinetto, P. M. & Bertini, C. (2008) On modeling the rhythm of natural languages. Proc. of the 4th International Conference on Speech Prosody, Campinas 2008, 427-430.
- Bertini, C. & Bertinetto, P. M. (2009) Prospezioni sulla struttura ritmica dell'italiano basate sul corpus semi-spontaneo AVIP/API. Proc. of the AISV Congress (Associazione Italiana di Scienze della Voce), Arcavacata (CS), 3-5 December 2007, 3-21.
HTML, CSS and design by Paolo Mairano